「オブジェクト指向って、なんとなくわかった気がするけど、実際どう使うの?」——そう感じているエンジニア研修生、あなただけじゃありません。
プログラミングを学び始めると、必ずといっていいほどぶつかるのがオブジェクト指向の壁。教科書を読んでも「クラスってなに?」「継承って何が便利なの?」とモヤモヤしたまま進んでしまう人が後を絶ちません。
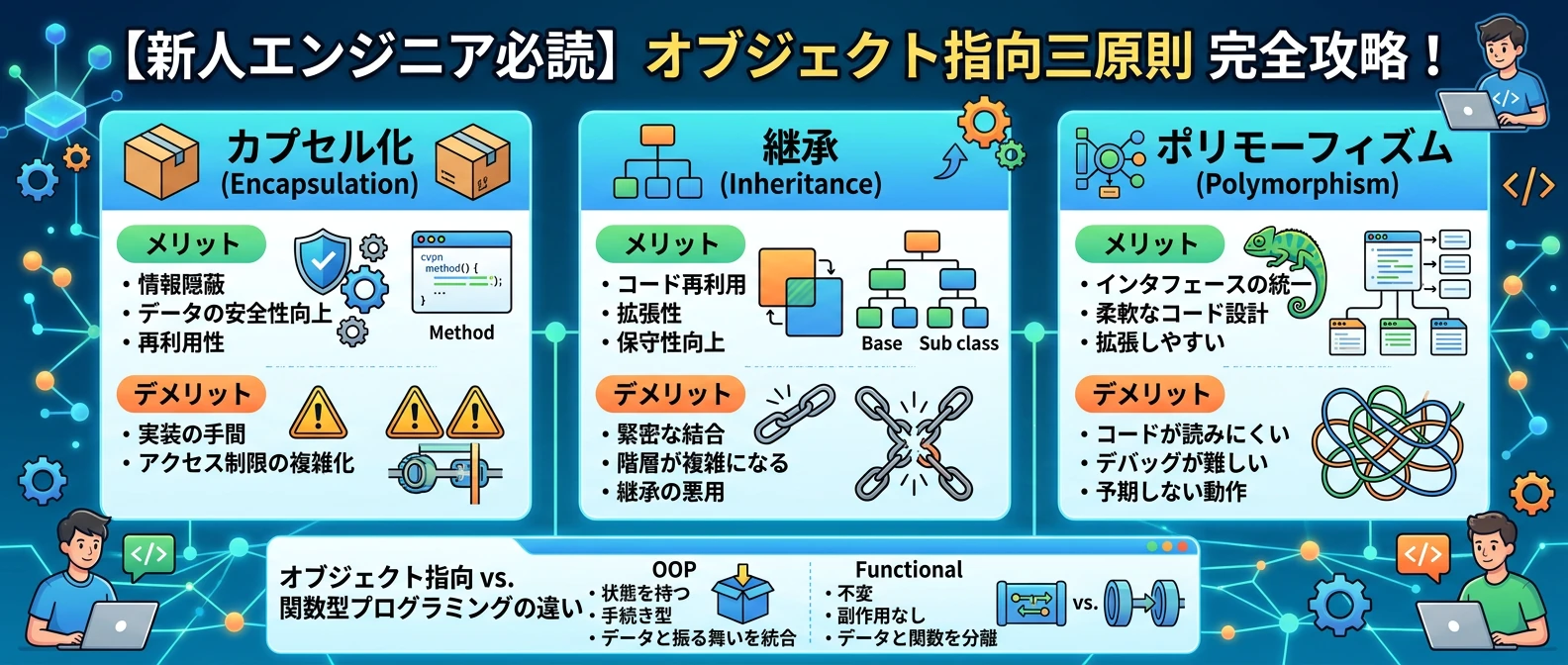
この記事では、IT業界の研修現場で積み上げてきた知見をもとに、オブジェクト指向の3大特性(カプセル化・継承・ポリモーフィズム)を日常の例えとコードで解説。さらに各原則のメリット・デメリットと、近年注目される関数型プログラミングとの違いまで踏み込みます。読み終えるころには、設計の選択肢が一段と広がっているはずです!
目次
- この記事を読む前に知っておきたい前提知識
- 【大項目①】カプセル化 ── データを守る「黒い箱」の仕組み
- 【大項目②】継承 ── コードを「親から子へ」引き継ぐ魔法
- 【大項目③】ポリモーフィズム ── 「同じ呼び方、違う動き」の柔軟設計
- 【番外編】関数型プログラミングとの違いを理解しよう
- まとめ ── 3大原則+αを現場で活かすために
この記事を読む前に知っておきたい前提知識
この記事は、以下の知識を持っている方を対象にしています。
- Javaなど、オブジェクト指向言語を学習中(または学習予定)の方
- 変数・メソッド・クラスという言葉を聞いたことがある方
- プログラミングの基本的な書き方(if文・for文など)を理解している方
「クラスって何?」という段階の方は、まず「クラスとはオブジェクトの設計図」というイメージを持っておいてください。家の設計図(クラス)があれば、同じ構造の家(オブジェクト)をいくつでも建てられる——このイメージが、以下の3大原則を理解する土台になります。
【大項目①】カプセル化 ── データを守る「黒い箱」の仕組み
カプセル化ってそもそも何?
カプセル化(Encapsulation)とは、データ(属性)と処理(メソッド)をひとつのクラスにまとめ、外部から直接触れないように隠蔽する仕組みです。
身近な例で言うと、車のエンジンがまさにカプセル化そのものです。私たちはエンジンの内部構造を知らなくても、アクセルとブレーキというインターフェースだけで運転できますよね。内部の複雑な仕組みは隠されていて、私たちは決まった操作口からしかアクセスできない——それがカプセル化の本質です。
実装の具体的なイメージ(Java例)
public class BankAccount {
private int balance; // 残高:外部から直接触れない(private)
// 残高を確認するための窓口(publicメソッド)
public int getBalance() {
return balance;
}
// 入金するための窓口
public void deposit(int amount) {
if (amount > 0) {
balance += amount;
}
}
}残高(balance)に private をつけることで、外部から直接 balance = -99999 のような不正な書き換えを防げます。アクセスは必ず決められたメソッド経由——これがカプセル化の安全装置です。
✅ カプセル化のメリット
- 安全性の確保:外部から直接データを変更できないため、意図しない値の書き換えやバグの混入を防げます。銀行口座の残高が「どこからでも書き換え自由」では困りますよね。それを防ぐのがカプセル化です。
- 保守性の向上:内部実装を変更しても、外部のインターフェース(メソッド名)さえ変えなければ、呼び出し元のコードを修正する必要がありません。変更の影響範囲をクラス内に閉じ込められます。
- チーム開発の効率化:「このクラスはこのメソッドを通じて使う」というルールが明確になるため、担当者ごとの実装の分業がしやすくなります。
⚠️ カプセル化のデメリット・注意点
- コード量が増える:すべての属性に対してgetterやsetterを用意すると、シンプルなデータ構造でもコードが膨らみがちです。過剰なカプセル化は逆に可読性を下げることもあります。
- 設計スキルが求められる:「どこまでprivateにするか」「どのメソッドを公開するか」という判断には設計センスが必要です。初学者のうちは、何でもpublicにしてしまいがちな点に注意しましょう。
- 過剰なカプセル化は逆効果:必要以上に隠蔽すると、テストや外部連携が困難になるケースもあります。「適切に隠す」という感覚が大切です。
カプセル化の3つの結論
- ✅ 結論①:データと処理をひとまとめにすることで、クラスの内部構造を外部から隠蔽できる
- ✅ 結論②:private・publicの使い分けにより、意図しないデータ操作を防ぎ、安全性が高まる
- ✅ 結論③:バグの発生源がクラス内に局所化されるため、デバッグと保守のコストが大幅に下がる
【大項目②】継承 ── コードを「親から子へ」引き継ぐ魔法
継承ってそもそも何?
継承(Inheritance)とは、既存のクラス(親クラス=スーパークラス)の属性やメソッドを、新しいクラス(子クラス=サブクラス)が引き継いで使える仕組みです。
日常的な例えで言うと、「乗り物」という大きなカテゴリがあったとして、そこから「自動車」「自転車」「バイク」がそれぞれ派生していくイメージです。どれも「移動できる」という共通の特性(メソッド)を持ちながら、それぞれ固有の動きを持っています。
実装の具体的なイメージ(Java例)
// 親クラス:乗り物
public class Vehicle {
protected String name;
public void move() {
System.out.println(name + "が移動します");
}
}
// 子クラス:自動車(Vehicleを継承)
public class Car extends Vehicle {
public Car() {
this.name = "自動車";
}
// 自動車固有の動作を追加
public void honk() {
System.out.println("クラクションを鳴らします");
}
}Car クラスは Vehicle を継承しているので、move() メソッドをそのまま使えます。同時に、honk() という自動車だけの機能も追加できる。共通部分は親にまとめ、固有部分だけ子に書く——これが継承の美しさです。
✅ 継承のメリット
- コードの再利用性:親クラスに共通処理をまとめることで、同じコードを何度も書く必要がなくなります。修正も親クラス1か所で済むため、変更漏れのリスクが激減します。
- 拡張性の高さ:新しい機能を持つクラスを追加するとき、親クラスを継承するだけで既存の処理を引き継げます。「ゼロから書く」必要がなく、開発スピードが上がります。
- 現実世界のモデル化:「自動車は乗り物である(is-a関係)」という現実の階層構造を、そのままコードで表現できます。設計の意図が伝わりやすくなります。
⚠️ 継承のデメリット・注意点
- 親子の強い結合(密結合):親クラスの変更が、意図せず子クラスの動作に影響を与えることがあります。「親を直したら子が壊れた」という問題は、継承の深みにはまるほど起きやすくなります。
- 継承の多用は設計を複雑にする:継承の階層が深くなると、どのクラスがどのメソッドを持っているかを追うのが困難になります。「3階層以上の継承は要注意」と現場では言われます。
- is-a関係でない使い方はNG:「コードを流用したいだけ」という理由で継承するのは誤りです。その場合はコンポジション(has-a関係)の利用を検討しましょう。
継承の3つの結論
- ✅ 結論①:親クラスのコードを子クラスで再利用でき、同じ処理を何度も書く「コードの重複」を根本から防げる
- ✅ 結論②:親クラスを修正すれば全子クラスに変更が反映されるため、拡張性・保守性が格段に向上する
- ✅ 結論③:クラス階層を使って現実世界の「is-a関係」を自然にモデル化できる(ただし深い階層は逆効果)
【大項目③】ポリモーフィズム ── 「同じ呼び方、違う動き」の柔軟設計
ポリモーフィズムってそもそも何?
ポリモーフィズム(Polymorphism)とは、同じインターフェース(メソッド名)を通じて、異なるクラスが異なる処理を実行できる仕組みです。「多態性」とも呼ばれます。
日常の例えで言うと、テレビのリモコンの電源ボタンがまさにそれ。どのメーカーのテレビでも「電源ボタンを押す」という操作は同じですが、内部的な処理はメーカーによって異なります。操作する側は「電源ボタンを押す」という統一した手順だけ知っていればいい——それがポリモーフィズムの力です。
実装の具体的なイメージ(Java例)
// 共通の抽象クラス
public abstract class Shape {
public abstract void draw(); // 共通メソッド
}
// 円クラス
public class Circle extends Shape {
public void draw() {
System.out.println("○ 円を描きます");
}
}
// 四角クラス
public class Rectangle extends Shape {
public void draw() {
System.out.println("□ 四角を描きます");
}
}
// 使う側:Shape型でまとめて扱える!
Shape[] shapes = { new Circle(), new Rectangle() };
for (Shape s : shapes) {
s.draw(); // 同じ呼び方で、各クラスの処理が動く
}draw() という同じメソッド名で、円は円の描き方、四角は四角の描き方を実行します。新しい図形クラスを追加しても、使う側のコード(forループ部分)は一切変更不要です。
✅ ポリモーフィズムのメリット
- コードの統一性と可読性:処理の種類が増えても、呼び出し側は「同じメソッドを呼ぶだけ」でよくなります。条件分岐(if-else)だらけのコードが激減し、すっきりと読みやすくなります。
- 拡張に強い設計(開放閉鎖の原則):新しいクラスを追加するとき、既存のコードを変更せずに機能拡張できます。これはソフトウェア設計の原則「OCP(Open/Closed Principle)」そのものです。
- チーム分業の明確化:インターフェースさえ決めれば、各クラスの実装は別々のメンバーが並行して進められます。大規模開発での生産性向上に直結します。
⚠️ ポリモーフィズムのデメリット・注意点
- 動作の追跡が難しくなる:「このメソッドを呼んだとき、実際にどのクラスの処理が動くのか?」がコードを見ただけではわかりにくくなります。デバッグ時に混乱しやすい点には注意が必要です。
- 過剰な抽象化はかえって複雑に:将来の変更を見越して抽象化を進めすぎると、「何のためのクラスか」がわかりにくくなります。「今必要な抽象化だけを行う(YAGNI原則)」が鉄則です。
- インターフェース設計の質が問われる:共通インターフェースの設計が甘いと、後から修正するコストが大きくなります。設計段階での慎重な検討が必要です。
ポリモーフィズムの3つの結論
- ✅ 結論①:同じメソッド名で異なるクラスの処理を統一的に呼び出せるため、コードのシンプルさと一貫性が保たれる
- ✅ 結論②:新しいクラスを追加しても既存コードを変更する必要がなく、「開放閉鎖の原則」に沿った安全な拡張ができる
- ✅ 結論③:インターフェースを共通化することで、チーム開発での分業が明確になり、並行作業がスムーズになる
【番外編】関数型プログラミングとの違いを理解しよう
そもそも「関数型プログラミング」って何?
オブジェクト指向の対比としてよく挙げられるのが関数型プログラミング(Functional Programming)です。近年、JavaやPythonなどの主要言語にも関数型の特徴が取り入れられ、現場エンジニアにとって避けて通れない概念になっています。
関数型プログラミングの核心は、「データを変更せず、関数を組み合わせて処理を表現する」という考え方です。数学の関数のように「同じ入力には必ず同じ出力が返る(副作用のない処理)」を理想とします。
オブジェクト指向 vs 関数型:考え方の根本的な違い
| 観点 | オブジェクト指向(OOP) | 関数型(FP) |
|---|---|---|
| 中心的な概念 | オブジェクト(データ+処理) | 関数(入力→出力の変換) |
| 状態の扱い | オブジェクトが内部に状態を持つ | 状態の変更を避ける(イミュータブル) |
| 処理の表現 | メソッドの呼び出しで状態を変化させる | 関数の組み合わせ(合成)で処理を表現 |
| 副作用 | 状態変化(副作用)を前提とした設計 | 副作用をできる限り排除する |
| 得意な場面 | 大規模業務システム、UIコンポーネント | データ変換処理、並行処理、ストリーム処理 |
| 主な言語例 | Java、C#、Python(OOP側面) | Haskell、Scala、Clojure、Elixir |
Javaで見る「OOP的な書き方」vs「関数型的な書き方」
同じ「リストから偶数だけを取り出す」処理を比べてみましょう。
OOP的なアプローチ(命令型):
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
List<Integer> evens = new ArrayList<>();
for (int n : numbers) {
if (n % 2 == 0) {
evens.add(n); // リストの状態を変化させる
}
}
// evens → [2, 4, 6]関数型的なアプローチ(Java Stream API):
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
List<Integer> evens = numbers.stream()
.filter(n -> n % 2 == 0) // 条件を「関数」として渡す
.collect(Collectors.toList());
// evens → [2, 4, 6]関数型アプローチは「何をしたいか(What)」を宣言的に記述します。OOP的アプローチは「どうやるか(How)」を手順として記述します。どちらが優れているという話ではなく、場面によって使い分けるのが現代の開発スタイルです。
✅ 関数型プログラミングのメリット
- テストのしやすさ:同じ入力には必ず同じ出力が返るため、ユニットテストが非常にシンプルになります。副作用がないので、テスト環境の準備が最小限で済みます。
- 並行処理との親和性:データを変更しない(イミュータブルな)設計は、複数のスレッドが同じデータを扱う並行処理において競合状態(race condition)を防ぎやすくなります。
- コードの簡潔さ:Stream APIやラムダ式を活用することで、ループや条件分岐を短く宣言的に書けます。意図が伝わりやすく、バグも入り込みにくくなります。
⚠️ 関数型プログラミングのデメリット・注意点
- 学習コストが高い:「イミュータブル」「高階関数」「モナド」など、OOPとは異なる概念体系を習得する必要があります。慣れるまでに時間がかかることが多いです。
- 状態管理が複雑になるケースも:状態の変更を完全に排除しようとすると、逆にコードが複雑になることもあります。現実のビジネスシステムでは、状態を持つことが自然なケースも多いです。
- チームのスキルセットが問われる:チーム全員が関数型の考え方を理解していないと、コードレビューや保守が難しくなります。導入には段階的なアプローチが有効です。
結論:OOPと関数型は「対立」ではなく「補完」の関係
重要なのは「どちらが正しいか」ではありません。現代の開発現場では、OOPと関数型の考え方を組み合わせるハイブリッドアプローチが主流です。
- 大枠の設計・役割分担 → オブジェクト指向で整理
- データ変換・集計処理 → 関数型(Stream/ラムダ)で簡潔に記述
「使い分ける視点」を持つことが、一段上のエンジニアへの近道です。
まとめ ── 3大原則+αを現場で活かすために
オブジェクト指向の3大特性と関数型プログラミングの要点を整理しましょう。
| 原則・概念 | 一言で言うと | 最大のメリット | 主な注意点 |
|---|---|---|---|
| カプセル化 | データを守る黒い箱 | 安全性・保守性の向上 | 過剰な隠蔽はテストを困難にする |
| 継承 | 親から子へコードを引き継ぐ | 再利用性・拡張性の向上 | 深い階層は密結合と複雑さを生む |
| ポリモーフィズム | 同じ呼び方、違う動き | 柔軟性・拡張への強さ | 動作追跡が難しくなる場合がある |
| 関数型プログラミング | 関数で処理を組み立てる | テストしやすく並行処理に強い | 学習コストが高く、習熟に時間がかかる |
オブジェクト指向の3原則は、バラバラに覚えるのではなく「セットで使ってはじめて力を発揮する」ものです。カプセル化でデータを守り、継承でコードを再利用し、ポリモーフィズムで柔軟に拡張する。そして、データ処理の場面では関数型の視点を取り入れてさらに洗練させる——この流れを意識するだけで、書くコードの品質がワンランク上がります。
研修の場で「なぜこの書き方をするの?」と感じたとき、ぜひこの4つの視点で問い直してみてください。きっと設計の意図が見えてくるはずです。まずは小さなクラスを一つ作ってみること。それが、オブジェクト指向マスターへの第一歩です。一緒に頑張っていきましょう!💪
コメントを残す